[试错]有趣的 Radio Test
Table of Contents
这个小项目是这两天突然心血来潮想到的,因为奶爸是一个域名收藏爱好者(不敢称投资人),平常有些域名,比如 hulu.com tiktok.com 这种朗朗上口的域名非常令人向往。
而一些普通的易读但是非单词的纯字母域名可能会隐藏在某些一口价里面且很难去筛选,之前在老外群里面跟 Native Speaker 交流,他们有一个非常原始且有效的评估域名的方法:Radio Test。那么奶爸就在想,能不能借助机器学习的能力来做到自动化 Radio Test。
TL;DR; 这个项目夭折了,现在 TTS、STT 的技术还达不到 radio-test 的要求。
测试步骤
既然是 Radio Test,那肯定是先说出来让别人听到,再去模拟人耳听这个读音转换成文字,对比原始文字和经听写后的文字,如果一致是最好的。
0x TTS 文字转语音
所以我就先从第一步开始,找了一下 Text-to-Speech (TTS) 相关的技术,没有找到比较好的 rust binding,试了几个现有的 binding 都是有两个问题:
- 发不出声音来,我这音频都是开的,音量也很大,就是不出声
- 不能将声音写到文件中,因为 TTS 之后我要处理、评分的
然后找了 star 排行里面的 Mozilla TTS 和 coqui TTS 做了一下比较,coqui TTS 的发音更胜一筹,不过也发现一点小问题,读句子问题不大,在读单个词的时候会出现脑瘫症状:

在读 「naiba」的时候,是这样的
而换成 「naiba.」就正常了,推测跟 stopword 有关系
1xSTT 语音转文字
文字转语音算是解决了,下一步我们通过机器学习赋能,把语音再转换为文字,这样就相当于做了 radio test 了。
语音转文字奶爸选择的是 https://github.com/mozilla/DeepSpeech ,它有 rust binding,奶爸的初心也是继续夯实自己的 rust 编码能力,所以首选 rust 技术栈,成功把语音转换为了文字。
经过测试,如果是词典里面有的单词的 TTS 能够正常转换出来,可是字典里面没有的,比如「zoho」、「Google」、「Waza」识别效果都不好,因为想 「zoho」这个词本身 TTS 读出来就少了音节,奶爸就先把精力又放回了 TTS 这里,看了下现在用的 Docker 还是 TTS 0.1 版本的,索性奶爸就自己做了个新版本的 Docker 镜像,然后把 TTS 提供的各种预训练 model 都试了个遍,依旧不能很好的把上面几种疑难词复原回来。
至此,宣告,此次尝试失败。
2xScore 打分
其实如果 TTS->STT 这一步比较理想的把类似「Zoho」、「Google」、「Hulu」这种好词给复原出来的话,我还准备做一个域名 Radio-Test 的打分机制呢,其实在网上找了几个音频可视化的工具看了下,比如 这样的
还有 这样的 这个就明显是我想要看到的样子
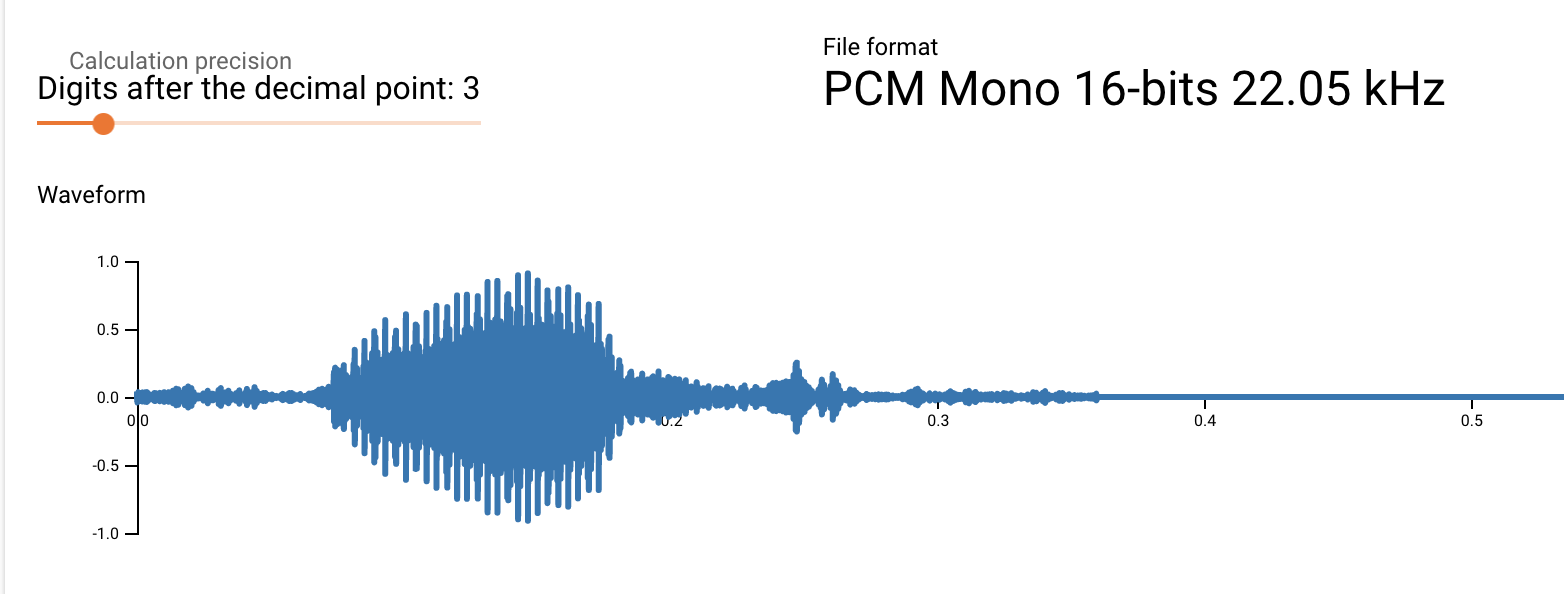
其实我的设想就是:
- 扣分制,满分 100 分
- TTS -> STT 对比原始字符串跟恢复后的字符串的差异,每个多出来的字 -5 分,每个漏掉的字 -10 分
- 通过波形以一个算法算出「读音数」,比如 book 算两个,see 算一个,超过 2 个的每个 -10 分
最后出一个:
nai.ba 100 分
这个意思,
Docker 用法
独乐乐不如众乐乐,之前发表博文时并未加入使用方法,加上奶爸还比较好奇「中文」model 下的运行效果,所以这次 2021 年 10 月 11 日,回过头来把中文模型下的使用方法及运行效果发一下。
使用说明
version: "3.3"
services:
dashboard:
image: ghcr.io/naiba/coqui-tts
entrypoint:
[
"tts-server",
"--model_name",
"tts_models/zh-CN/baker/tacotron2-DDC-GST",
"--vocoder_name",
"vocoder_models/universal/libri-tts/fullband-melgan",
]
ports:
- 5002:5002
使用效果
-
naiba
-
奶爸
还是那么沙雕 😕
Comments
哈哈哈,笑死我了!
https://aoaotts.vercel.app/?text=%E5%A5%B6%E7%88%B8%E6%98%AF%E5%82%BB%E9%80%BC 你试试
@Dark 这个效果不错,估计是商业API,想要开源的